In the good old days, an average web application’s structure was relatively simple. The n-tier architecture typical for these times represents what almost every person imagines if you ask them how a web app is built. Namely, there should be a backend part, a middle-tier business logic part, and the UI for users to interact with the system. That’s precisely how you build an app as a monolith.
Cloud-based applications have brought new requirements, challenges, and patterns. Agile delivery of new features as a quick response to rapidly changing user demands and requirements has become quite a challenge. Plus, the resources should be utilized optimally to reduce the cost of building and maintaining such complex structures. As a result of these demands, the microservices architecture appeared. Today, we’ll consider the basic features of monolithic architecture, distributed monoliths, and microservices.
App as a Monolith. Putting All Your Eggs in One Basket
The term “Monolith” quite eloquently describes the architecture of web applications typical for the client-server era. Here, the whole app comprises several tiers, and a specific set of technologies is used to implement each of them. In a monolith system, you can usually find such functional layers as web, business logic, and data:
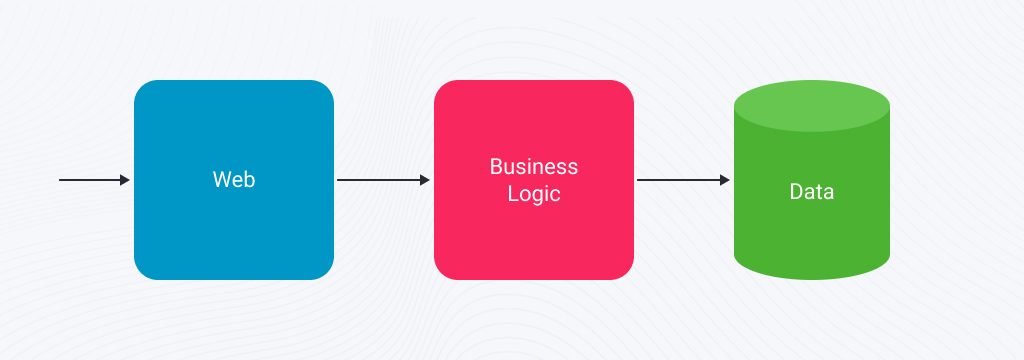 Suppose you decide to build a web application to sell goods online. It doesn’t matter what exactly you want to sell. We’ll only focus on the core functionality of such apps to illustrate our example. In such a system, the parts you need to implement might look like this:
Suppose you decide to build a web application to sell goods online. It doesn’t matter what exactly you want to sell. We’ll only focus on the core functionality of such apps to illustrate our example. In such a system, the parts you need to implement might look like this:
- inventory component;
- recommendation engine that reacts to what users input into the search bar;
- cart service;
- payment engine;
- reporting component.
Make everything right, and voila, you’re a pride owner of the online shopping portal:
 If you build such a portal as a monolith within the tiers shown above, the components will be closely tied and highly dependent. Later, you may decide to add new features. If you want to make some changes to the monolith, you need to know what’s inside the components and how they are connected to each other. It’s the only way to ensure you won’t break something. In a monolith, it’s much easier than you think.
If you build such a portal as a monolith within the tiers shown above, the components will be closely tied and highly dependent. Later, you may decide to add new features. If you want to make some changes to the monolith, you need to know what’s inside the components and how they are connected to each other. It’s the only way to ensure you won’t break something. In a monolith, it’s much easier than you think.
Back in the days, building web apps as monoliths was a natural and optimal response to the existing infrastructural limitations and lack of desired agility. As a result, some inefficiencies started to appear over time. When you can’t deliver distributed applications and have to work with a few tiers with tightly coupled components inside them, you may face problems when introducing even tiny changes. In this case, you’ll have no other choice than retesting and redeploying the whole tier. A tiny update of one component within the business logic layer of a monolith might have unforeseen effects on the rest of the tier, which requires prolonging the development cycles and performing thorough testing.
Achieving the required performance while working with data stored in the backend is another challenge for web applications built as a monolith. Typically, the solution was to add intermediate caches for buffering. It helps to smooth out the inefficiencies between the parts of the system where data is stored and where all the computing is carried out. However, such an approach has its downsides. For example, it increases the overall costs because you need to add new hardware, and new development complexities will appear.
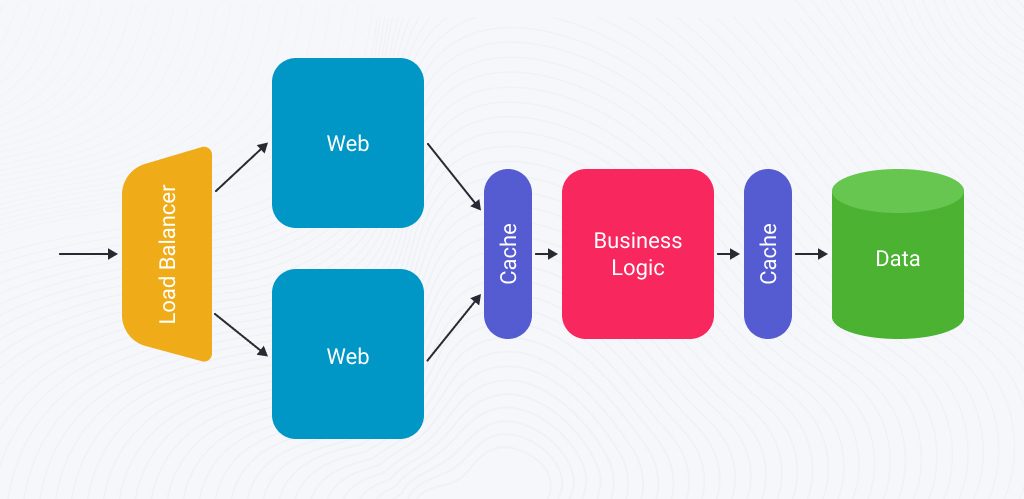 To scale the monolith, you can, for instance, allocate more resources or clone it across multiple servers:
To scale the monolith, you can, for instance, allocate more resources or clone it across multiple servers:
Benefits
The simple design enables easy development and management. Monoliths have a pretty straightforward structure. Such systems are easier to design. Since all involved developers and testers work on a homogenous single product, it’s easier to manage the project life cycle and perform quality assurance procedures, which results in more efficient use of resources.
Faster calls between components within the monolith can be achieved thanks to their close ties and interprocess communication (IPC) use.
Challenges
Language and framework dependency. If you work with a Java application built as a monolith, all additional components must also be written in Java. It limits your possibilities by decisions made in the past since you can’t simply introduce a new component built with different technologies.
Growth issues. Over time, user expectations regarding the app’s functionality may grow. Sooner or later, you’ll have to add new features to keep everybody happy. Adding new capabilities into the monolith makes it harder for the team to understand everything that happens under the system’s hood.
Deployment problems. The larger the monolith grows, the more deployment problems appear. One sunny day, the team may need to shut down the original application, deploy the new production version, and spend who-knows-how-many hours to make it functional again.
Scaling difficulties. Suppose there are too many new users on your shopping portal, and the payment component of our imaginary web application can’t process all the payments. Since inside the monolith, all components are tied together, scaling just some of them can be challenging. You’ll need to redeploy the entire application to introduce changes to one single feature. If it’s only a temporary influx of new users, the interest in what your portal offers may be gone pretty fast. Maybe long before you deploy and test the latest version of your monolith application, resulting in wasted efforts.
Microservices. Functionality Distributed Across Multiple Containers
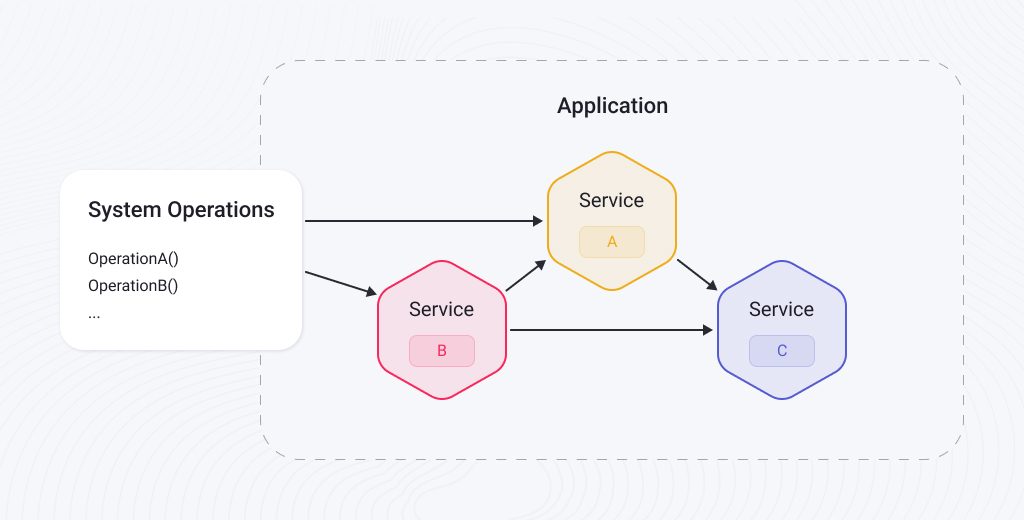
In the microservices architecture, the functionality of a system as a whole is distributed across smaller, separated parts. “What is a microservice actually?” you may ask. After all, don’t regular web apps consist of small functional parts, be they built following a monolithic approach or any other? Can’t we call them microservices as well? To answer these questions, let’s take a look at some of their characteristics that are considered generally accepted:
- Implements a specific business scenario that solves a particular problem;
- Built by small development teams;
- Implemented with any programming language, framework, or library, resulting in a unique tech stack;
- Includes code and also may include state. They both are versioned, deployed, and scaled independently;
- Communicates with other microservices using a wide variety of tools, including gRPC, REST APIs, GraphQL, event streaming, message brokers, etc.;
- Remains consistent and available during failures.
Let’s return to the example of the online shopping portal from the previous chapter. Rewriting the monolith according to the microservices approach will result in distributed components implementing the same functionality, running in their own containers, deployed across a cluster of machines, and talking with each other over APIs. Such services can be developed by smaller teams that independently test, version, deploy, and scale them, ensuring the continuous evolution of the system as a whole.
Read Also Micro-frontends: The Future Sometimes Comes in Miniature Sizes
The ability to choose any programming language for a specific part provides developers with due agility. This feature of microservices may become both a blessing and a curse. We’ll consider it more closely later in this article.
To communicate with each other, distributed components often use the REST approach and HTTP and TCP protocols. As a serialization format, XML or JSON can be used. In theory, nothing stops developers from using their own protocols if the described approaches don’t satisfy their needs. However, in this case, people who use and maintain these not openly available formats will have some bad times.
Since we work with a distributed system in the case of microservices architecture, dealing with unexpected failures becomes much more complex than in the case of monoliths. Here, you don’t deal with a highly centralized system. That’s why you must somehow prepare yourself for a situation where a single machine running a specific service fails, and you need to detect and restart it. Microservices’ resiliency and their ability to restart on another machine are vital. If you work with sensitive user information, another critical aspect is the integrity and consistency of the data these distributed services work with. If there’s a failure during the upgrade, the microservice should determine whether it can move to the newer version. If not, it must roll back to the previous version to maintain consistency. To decide whether there are still enough machines to move forward and how to restore the previous version, components must report health and diagnostics information.
Creating and managing diagnostic events across a distributed network of containers is also challenging. Besides being a complex task by itself, the situation is getting more complicated if we remember that different development teams may work on different services. They must agree on implementing standardized diagnostic events and logging formats.
Health monitoring implies that microservices report their state to help the team decide which actions to perform in a particular situation. In specific cases, the service itself may continue working while a particular machine reboots due to some unpredicted causes. Here, the service is considered unhealthy, and performing the upgrade is not recommended. The development team may wait until the machine is up and running again or conduct an investigation using the health monitoring tools. In such scenarios, health events help make informed decisions and create self-healing solutions.
The way you perform scaling in web apps built following the microservices architecture differs from how you make it with a monolith. Here, you can deploy distributed services independently by creating different instances across servers, virtual machines, or containers:
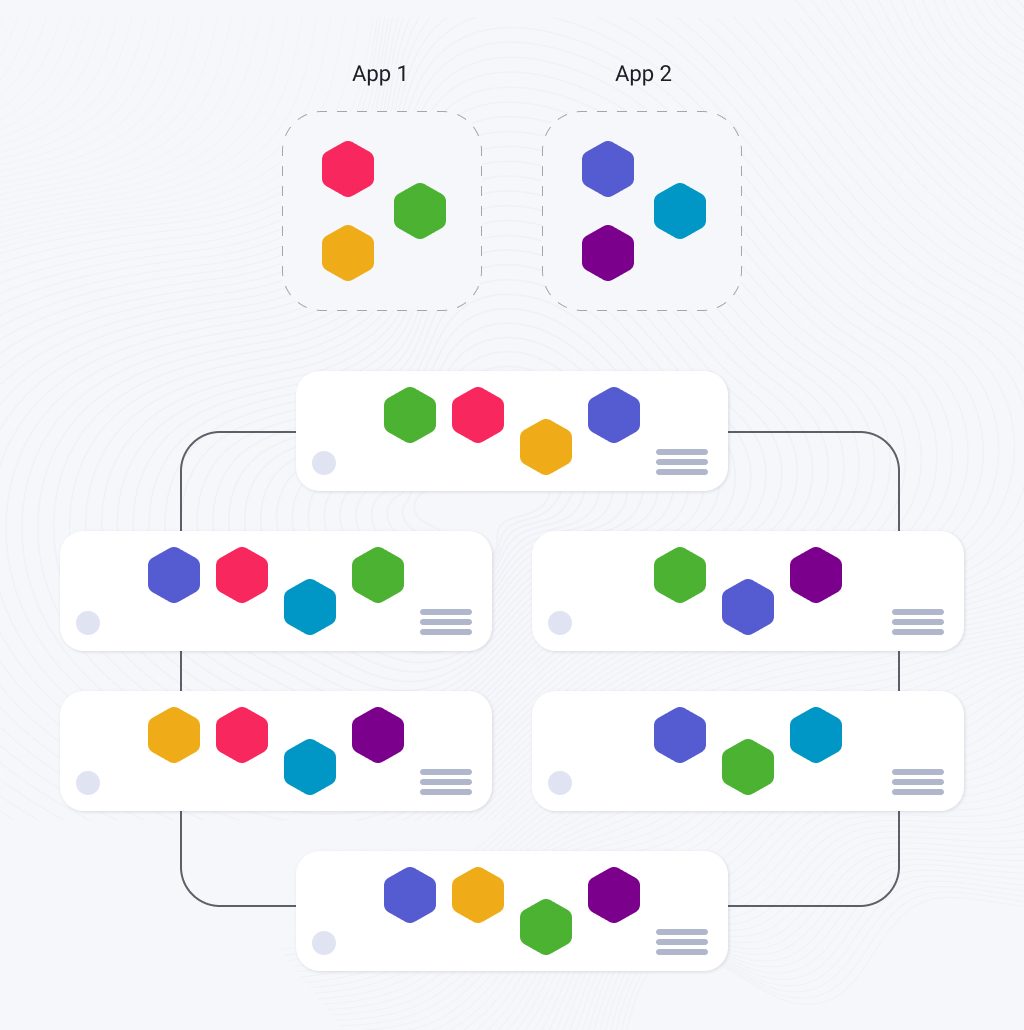
How Are Microservices Built?
First, microservices architecture requires DevOps and CI/CD since there are multiple small distributed components that you deploy frequently and independently. Unlike in the case of monoliths, here we speak of complex systems with multiple moving parts and different tech stacks.
Modern cloud applications are often designed as microservices that use containers. Inside them, you can find the application code and all the dependencies it needs to run. It allows developers to move containers from one environment to another without harming their functionality. Containers are smaller and lighter than virtual machines and fit this architecture well. Docker, a platform for building, sharing, and running container applications, is closely associated with microservice app development. Working with many containers is only possible with an efficient orchestrating tool. Kubernetes is an open-source container orchestration platform, one of the most popular solutions at the moment. It allows upgrading a single container when needed without affecting the entire system.
Services within the system communicate using APIs that allow them to share information and synchronize their work. API gateways are often used as intermediary layers between users and services. They’re especially useful when the overall number of components grows quickly over time. Here, API gateways route requests, distribute them among the available services and provide security and authentication features. Since Kubernetes is usually used for implementing a microservices architecture, developers typically use Ingress or (less often) Istino to build API gateways.
In the microservices architecture, an event is anything that happens within a specific component. For example, when the user adds or removes something from the cart, the system generates an event. If there are many distributed services and multiple people use the system simultaneously, these events are organized into event streams. It enables more efficient processing. Developers can analyze these events to understand how entities’ states change over time and take immediate action when something goes wrong. Apache Kafka, a stream-processing platform, may suit such kinds of tasks well. Following the Event Driven Architecture, developers can deliver solutions that process many messages in real-time mode.
Serverless computing allows developers to rely on a cloud provider responsible for maintaining and scaling the server infrastructure. The team can abstract from the underlying infrastructure, package their code in containers, and deploy them.
Additionally, many patterns help developers create efficient microservice applications, including:
- Backend-for-frontend (BFF) pattern;
- Adapter microservices patterns;
- Entity and aggregate patterns;
- Strangler application pattern;
- Service discovery patterns.
Benefits
Focus on business functionality. Each distributed service is an embodiment of a specific business feature. Developers that work on one of them are driven by a business scenario and not a particular technology. Smaller teams develop features to meet specific business requirements, use the tech that suits them better, and scale or modify services how and when they want.
Agile development and deployment. You can develop and deploy microservices independently, so it’s easier to manage upgrades and bug fixes. If you need to add extra features to the recommendation engine from our example, you don’t need to redeploy the entire application. The development team can put the required functionality into the DevOps pipeline, and once it’s tested for proper functionality, it can be automatically deployed into the corresponding container. Every team involved in the application development can deliver new features as quickly as possible, providing maximum value to the customer.
Independent scaling. The development team can scale a specific service independently. If you need to improve the performance of the paying component, the system can automatically add more capabilities. It can also scale down to its initial state when the load returns to normal. This way, microservices require fewer resources because they can scale where and when they need instead of scaling the entire system, like in the monolith case.
Smaller code bases with fewer dependencies. When working with a monolith, dealing with many dependencies is a day-to-day routine you have to put up with. Adding new features requires remembering that changes in one place affect other parts of the code base. In the case of microservices architecture, the lack of extra dependencies makes it easier to apply changes to distributed components and introduce new features.
Variety of technologies to choose from. Developers can choose the technology that helps solve the issue without considering what technologies are used in other parts of the system. The choice of a team that works on reporting services is independent of what the recommendation engine team has chosen. They can use the framework they know better or focus on the one that better fits a business feature they want to implement. Sometimes, choosing the tool that ensures better performance is better, while sometimes, the ease of development outweighs all other aspects. And microservices architecture enables such a freedom of choice.
Read Also What is a Tech Stack and How to Choose the Right One for Web Application Development
Fault isolation. The unavailability of a specific component doesn’t affect the entire system. To implement mechanisms for other distributed microservices to handle such failures, developers can rely on the Circuit Breaker pattern.
Challenges
It is hard to manage all the moving parts. Every service is a separate entity, and in microservices architecture, you have to manage dozens of such entities, including their development, deployment, and version control.
Challenging governance. Flexibility is not always good. The freedom of choosing any technology for distributed components implementation may lead to a system with too many languages and frameworks. At some point, maintaining such a versatile project may become hard. To avoid that, sometimes it’s essential to limit the flexibility of development teams and introduce some project-wide standards and limitations everybody should follow.
Network latency. In the microservices architecture, multiple distributed services communicate with each other intensively over the network. Network latency can become an issue if you create a very long chain of co-dependent parts. Therefore, you should pay attention to API design, avoid services that send too many messages, and find a place for asynchronous communication patterns like Queue-Based Load Leveling.
Data integrity. Each microservice works with its own data set, so keeping it consistent is one of the requirements.
Services updates. With a network of services depending on each other, you should perform updates carefully to avoid backward or forward compatibility issues.
Skill set. Developing a highly distributed microservices system requires special skills and expertise from the development team.
Distributed Monolith. A Monolith That Failed to Become a Microservices App
Distributed monolith is an excellent example of how one tries to take the best from two different approaches but only takes the worst from them instead. Here, you lose the simplicity of the monolith and don’t benefit from what distributed patterns offer.
In this scenario, developers split the monolith into a set of distributed services, but they’re still heavily dependent on each other. The desire to distribute a monolithic application across the multiple nodes of a network environment may be caused by different reasons, such as load balancing, redundancy, or some hardware limitations that need to be overcome. As a result, you’ll lose the advantage of fast calls between the components that the monolith provides since they’ll have to communicate over a network, resulting in latency.
Benefits
None specific to this architecture. This monolith type is typically a stepping stone to a more suitable architecture.
Challenges
Distributed monolith combines the downsides of monolithic and distributed systems, making it less than ideal for long-term use. It can lead to complexity without providing any apparent advantages.
How to Choose the Right Architecture?
Monolithic architecture is a good choice when your application is relatively simple, small to medium, and your development team is small or inexperienced. Monoliths can also be a suitable option for prototyping and early-stage development to get a product to market quickly or for developing MVP for your startup.
Read Also Proof of Concept in Software Development: Viable Alternative to MVP and Prototyping
Microservices architecture is ideal for complex and large-scale applications where different parts of the system have different scaling requirements, developed by different teams, and must be updated or replaced independently. It’s also beneficial when you want to use various programming languages or technologies.
Distributed monolith is not a recommended architectural pattern because it inherits some aspects of both monolithic and microservices architectures without any apparent benefits. Try avoiding it by any means possible.
Conclusions
Monolithic architecture is as simple and reliable as a brick, making it a good option for MVPs or solutions that don’t grow quickly over time. Microservices architecture is way more complicated to implement than the monolith due to multiple distributed components. It suits complex projects with many users and enables high accessibility, reliability, and scalability. Using the distributed monolith for your projects is a no-no, so try to avoid it. Contact us to get more information on the best-suited architecture of your application.