Big data is a huge topic nowadays. Every industry utilizes it, and most internet users feel its influence on themselves even if they do not know about it. Modern media and entertainment giants, as we know them, owe their success to big data. For example, it influences 80% of shows and movies watched on Netflix.
Healthcare, banking, retail, or any other industry you can think of is already benefiting from big data or could benefit from it with the right approach. According to the current state of affairs, big data is here to stay, and Statista predicts that the world of big data business is going to be worth more than $100 billion by 2027:
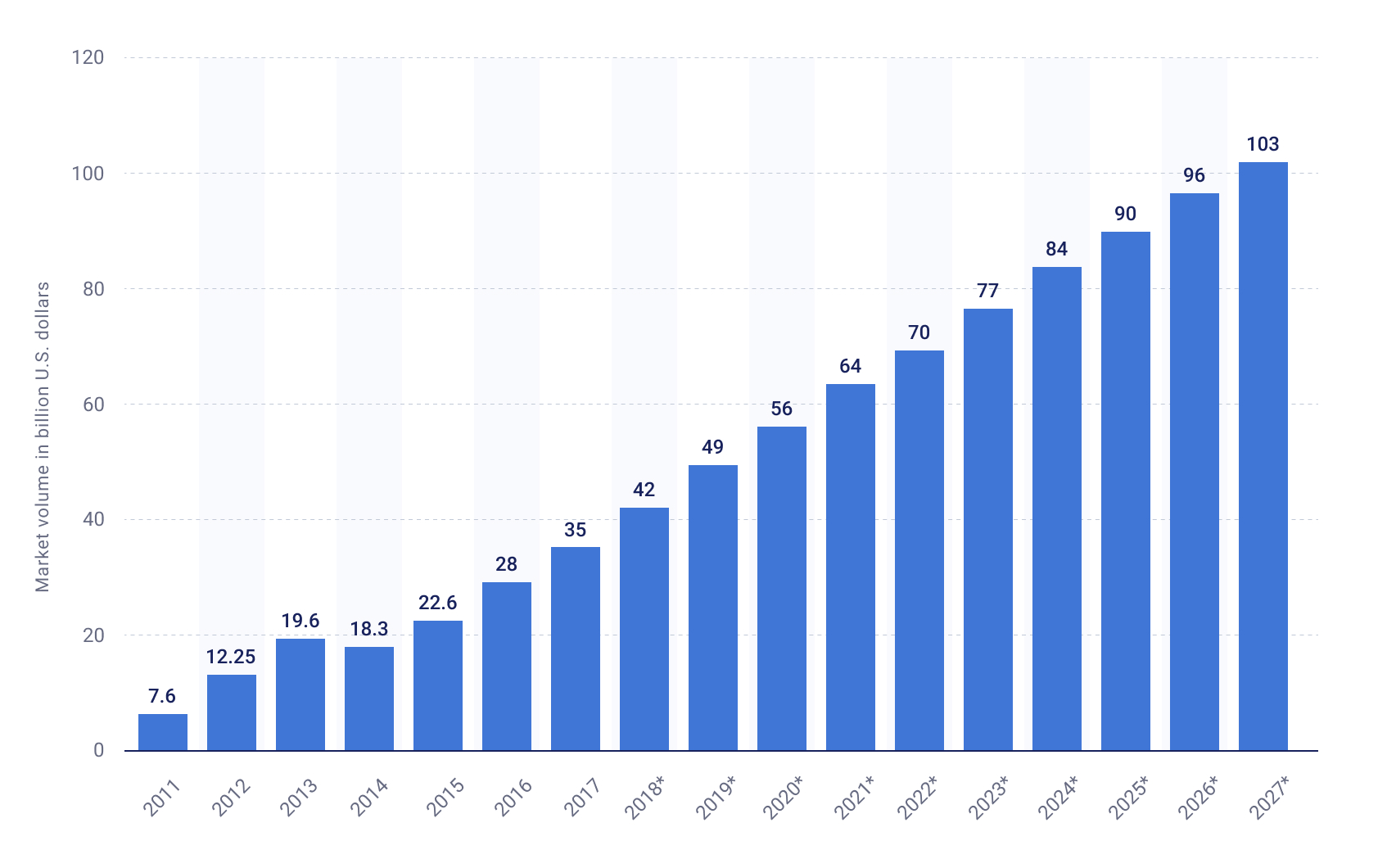 These statistics look breathtaking, but in the head of a person who has no experience working with big data, many questions arise. How much data must I collect before calling it “big data”? What are the types of big data, and how can I store it? Must I build a supercomputer to process big data and develop insights for boosting up my business?
These statistics look breathtaking, but in the head of a person who has no experience working with big data, many questions arise. How much data must I collect before calling it “big data”? What are the types of big data, and how can I store it? Must I build a supercomputer to process big data and develop insights for boosting up my business?
As you can imagine, answering these questions will take too much time. But luckily, we can shed some light on such an important topic as the significant points of divergence of such concepts as data lakes and warehouses. Understanding this distinction is pretty important since they both allow benefiting from the utilization of big data, but their purposes differ. Therefore, the peculiarity of the organization should be the determining factor when choosing one or the other option.
Key Differences Between Data Lake And Data Warehouse
It may be hard to determine the critical points of divergence between the two described phenomena at a glance. Both approaches help companies make informed decisions. But despite the apparent similarity, it’s essential to remember that mentioned terms describe entirely different approaches to the way you handle your data. First and foremost, data lakes are a way of accumulating and processing data without any predefined structure, the purpose of which is not determined at the moment. Just as lakes, warehouses were initially created for enabling enterprises to store large sets of information and process it. On the contrary to that approach, data warehouses contain data that was previously processed to match the following operations better.
Data Warehouses. Structured Data for Business Professionals
Despite the application in such a breakthrough area, data warehouses have not been invented in recent years to leverage big data analytics. They found widespread usage in the 1980s. Data warehouses were conceived to provide large enterprises with centralized access to info collected in a single location for further analysis to search for options to strengthen market positions. For example, businesses can use data warehouses for storing records on manufactured goods, made orders, delivered packages, and customers. Nowadays, there are a plethora of business intelligence apps allowing companies to represent such info intuitively and simplify the process of discovering essential patterns.
Read also Dashboard Development and Visualization Tools for Effective BI
According to the needs of a specific organization and its budget, warehouses can be deployed on-premises or in the cloud. In the first case, the company maintains and supports the physical hardware that stores the records. Cloud data warehouses like Amazon Redshift, for example, can free you from the lion’s share of activities related to data warehouse maintenance and are usually considered a more scalable and affordable option.
Data warehouses are commonly used for containing processed info which a broad audience can understand purpose and structure without deep expertise of scientific approach to the research. All the information that a warehouse contains has a specific purpose within the organization. Consequently, since data warehouses only contain info that can find practical applications, they do not require extensive storage space, which can be important for companies relying on on-premise servers. Processed data can be represented as a set of charts or tables, according to the specifics of the information. Such an approach allows any employee familiar with the represented topic to skim the data and enhance the used business processes.
Data Lakes. Raw Data for Data Scientists
Data lakes can contain any information, from images to JSON files. Besides the common types of files, lakes can use specialized formats intended specifically to process raw data, for example, sequence files storing binary key-value pairs. Raw data, in this case, stays unstructured and untouched until there’s the need for some transformation caused by the applications. This process approach is usually called “schema on read.” Because of the described method, data lakes require much larger storage space compared to warehouses.
The main feature of data lakes is that they store raw data that you have to process before extracting helpful “something” from it. The information flows from many small “streams” and large “rivers,” and at some point, it becomes an integral part of other information from the data lake. There’s no predetermined purpose for such data in most cases, and it’s stored in an unorganized way. Without specific knowledge in data science, it may be pretty hard to navigate in the lake. To recognize useful patterns across the variety of information, data scientists with specific skills use specialized tools intended to process seemingly unrelated data sets.
How to Choose Between Data Lake and Data Warehouse
Suppose you decide to cooperate with a company providing custom soft development services. In that case, most probably, you’ll be provided with detailed info describing the pros and cons of both approaches applicable to your specific business. However, it’s always good to be prepared and understand, at least in general terms, what path to big data storing will better work for your business.
Data warehouses can be a decent choice for a company that knows exactly what it collects and how it’ll boost the business. File formats, in this case, don’t change rapidly and are stored relatively static. Employees’ personal performance information and historical records related to customer relationships are excellent examples of such info. If a business relies on regular reports reflecting one or another side of the enterprise, the data warehouse will work just fine. Also, this option will be preferable if, according to laws and regulations, security is one of your top priorities.
As an alternative, you can rely on data lakes. These storages can become irreplaceable for any company that works in the data science field and doesn’t know what types of files or patterns it’ll store and process. If you work with datasets where different pieces of info have unclear relationships between them, you should probably prefer a lake. Also, it will suit you if you’re concerned that the amount of data to process will constantly be growing. Last but not least, data lakes will serve you better if your interests include predictive analytics or machine learning.
To make things more straightforward, let’s take a look at some examples. In finance and banking, a data warehouse can be considered as the best possible storage approach. Finance organizations know the type of information they work with and how to process it to improve productivity. Also, the records with which financial organizations work should be easily accessed by any employee with appropriate access and knowledge.
A cybersecurity company may collect extensive logs from routers and IoT devices, for example. These devices can record packets traveling across the network and save them if somebody decides to discover them in the future. Such info can be stored in a data lake for weeks and months until an unusual event, or a massive leak occurs. In such a case, a team of specialists can process the collected logs to find the cause of anomalies.
According to the specifics of your business, you can utilize both a data lake and a data warehouse. Say, a pharmaceutical company gathers tons of indicators reflecting a new drug trial results. The company may not know what exact side effects a drug may have or how it will affect a specific age group of subjects with certain chronic diseases. Therefore, such records can be stored in a lake, and a company may decide to process them in the future if needed. Also, such companies must strictly follow the regulations and have quick access to all the historical info related to the previous trial processes. For this purpose, the company can use a data warehouse.
Conclusions
Big data is a rich field for experimentation, and the vast possibilities it provides are astonishing. More and more companies from such various fields as manufacturing and entertainment are adopting these technologies to benefit from using an inexhaustible stream of business information. Data lakes and data warehouses are two approaches that determine how you store and process the info that reflect the flexibility of big data applications. The skillful use of these technologies or their combination will help you achieve a competitive edge whether you have complete control over the info you collect or not sure which pleasant surprises it hides.
If you want to start using big data benefits in your business but do not know where to start, contact us.