Summary
This article explores why software project estimates often differ wildly between vendors—sometimes by several times—even when based on the same requirements. It highlights key factors such as vague non-functional requirements, unpredictable system loads, and hidden complexity that all drive estimation variance. Finally, it emphasizes that the “correct” estimate is the one that aligns with your project’s real needs—and that an estimate should be treated as a starting point for discussion rather than an immutable promise.
Probably, you’ve already encountered a situation where, for the same description of work, different software vendors give estimates of labor costs that differ significantly. And we are not talking about a difference of a few percent. We’re talking about estimates that may vary by several times. Today, we’ll consider the main reasons for such discrepancies.
One Idea, Multiple Estimates
Suppose you have an idea to create a web app for an outlet store selling clothes online. You cooperate with an outlet store specialist and compose a scope scrupulously describing required features and the overall business process. With a designer, you draw some mockups to outline how your future web app will look like. If you have used such an application before, you have an idea of what set of functions they usually have.
Read Also How to Build an Ecommerce App and Live Happily Ever After
Next, you choose a region where you plan to start the application development. In that region, you find several potential software vendors and send them all your documents to get an estimate. After some time and several clarification meetings with these vendors, you can finally receive multiple estimates. The surprising thing in this story is that these estimates can range from X to n*X despite the same initial conditions.
One may find such a state of affairs confusing since all these vendors look the same, and their rates are not that much different:
- Where’s the difference coming from, then?
- Is someone dumping and underestimating?
- Or did someone put too many unjustified risks into the final cost?
All these factors have their influence, but there’s a more straightforward reason.
Read Also Switching Vendors? Here’s How We Take Over Your Project (No Panic Required)
Major Factors Affecting Estimates
Let’s consider the development of a pretty trivial feature for your imaginary web app that any similar app should have: log in with a username and password. On the surface, everything looks pretty simple. Users input their names and passwords, click the Login button, and the application performs an authentication and authorization routine. However, there are different ways the vendor can implement this feature.
Here, the vendor considers such factors as the application load (QPS or queries per second, sometimes called RPS or requests per second) and required UpTime. These are the parts of non-functional requirements that are often not included in the scope you send to vendors since your major concerns are functionality and the value of your application for users.
These parameters weren’t included in your requirements list, but they have a significant impact:
- QPS is the number of users that simultaneously perform specific actions. It changes during the day and depends on the particular day of the year. For example, in your outlet store web app, QPS will rise significantly before the holidays;
- UpTime shows how accessible your app is to users. UpTime equals 99% may look pretty awesome. However, it indicates that the app was inaccessible for 87 hours during the year. In other words, its downtime equals 87 hours. Unfortunately, it will be those hours when crowds of buyers want to buy their relatives some holiday gifts. For comparison, with all their financial and technical capabilities, Amazon AWS guarantees the downtime equals 4 hours, which gives us UpTime equals 99,95%. Such an excellent result!
Read Also Not Just a Manual: How Our Project Management Framework Helps Teams Deliver
Balancing Between Functionality and Implementation Cost
Typically, on an average day with low QPS, only a few users will utilize the Login feature at the same time. The standard approach of storing authorized user sessions is enough in this case. Implementation time is not required since it all works out of the box. Here, the implementation of the login feature takes X1 hours.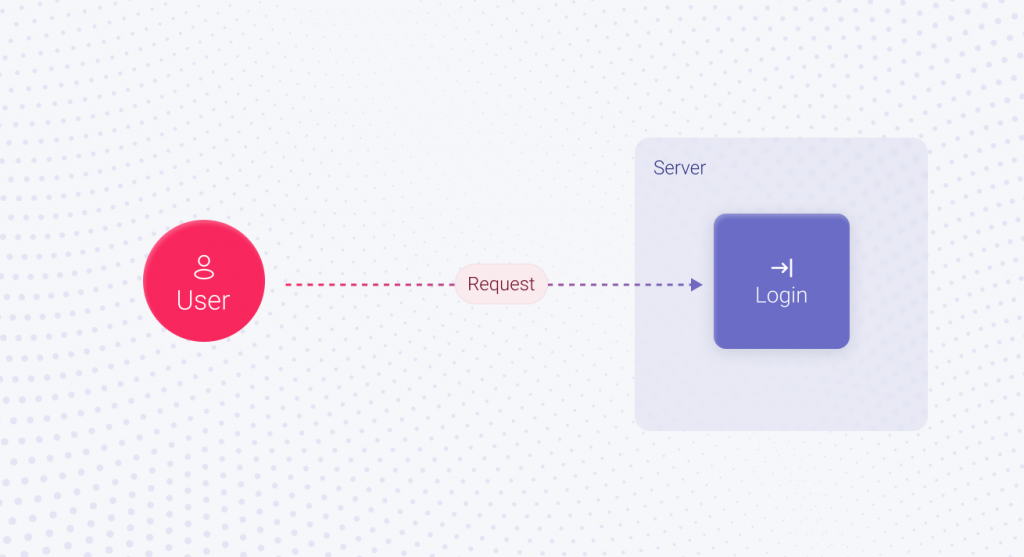 As time goes by, your application gains popularity and attracts new users. Black Friday is coming, and the number of users who want to buy something is skyrocketing. The standard approach we discussed won’t work in this case, and the session must be stored differently. For example, in Redis, the in-memory database. In this scenario, implementing the Login feature will take X2 hours. It’s not much more than X1, but still more.
As time goes by, your application gains popularity and attracts new users. Black Friday is coming, and the number of users who want to buy something is skyrocketing. The standard approach we discussed won’t work in this case, and the session must be stored differently. For example, in Redis, the in-memory database. In this scenario, implementing the Login feature will take X2 hours. It’s not much more than X1, but still more.
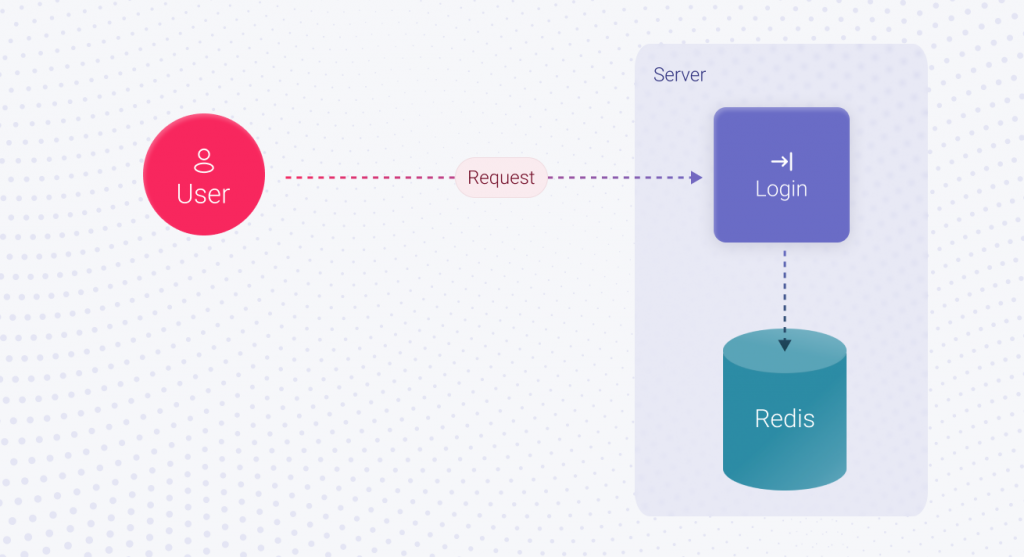
The next question is, what will be the financial consequences for your business if suddenly, on Black Friday, your application crashes and the user cannot log in? Of course, you can reach out to the vendor, and all the issues will be fixed. However, no one will give you back the lost time and bring back users who could not buy the desired product. If functionality is restored within an hour, it’ll be a good result, and the incident will increase overall downtime by 1 hour. It doesn’t seem much, but what is the amount of lost profit for 1 hour of rush demand you missed?
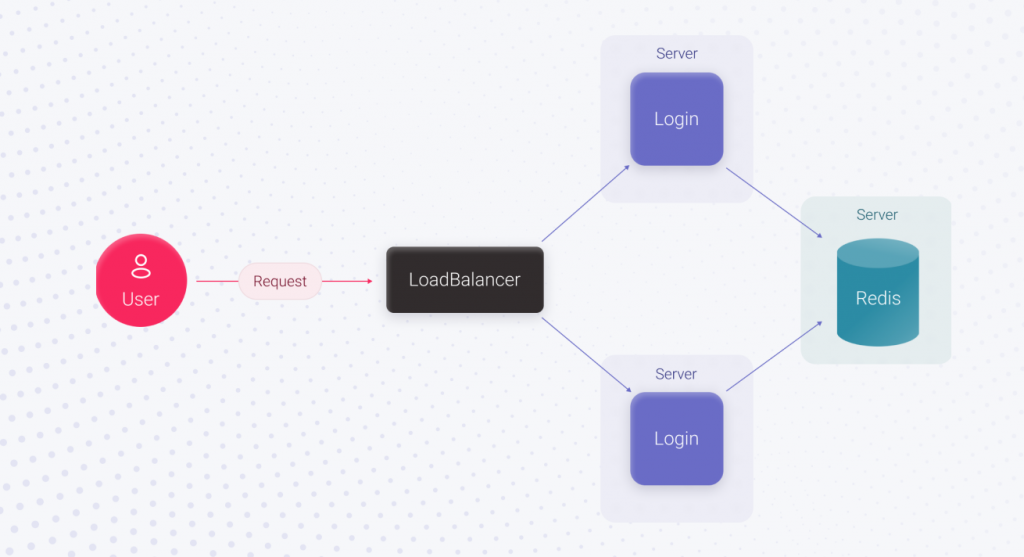
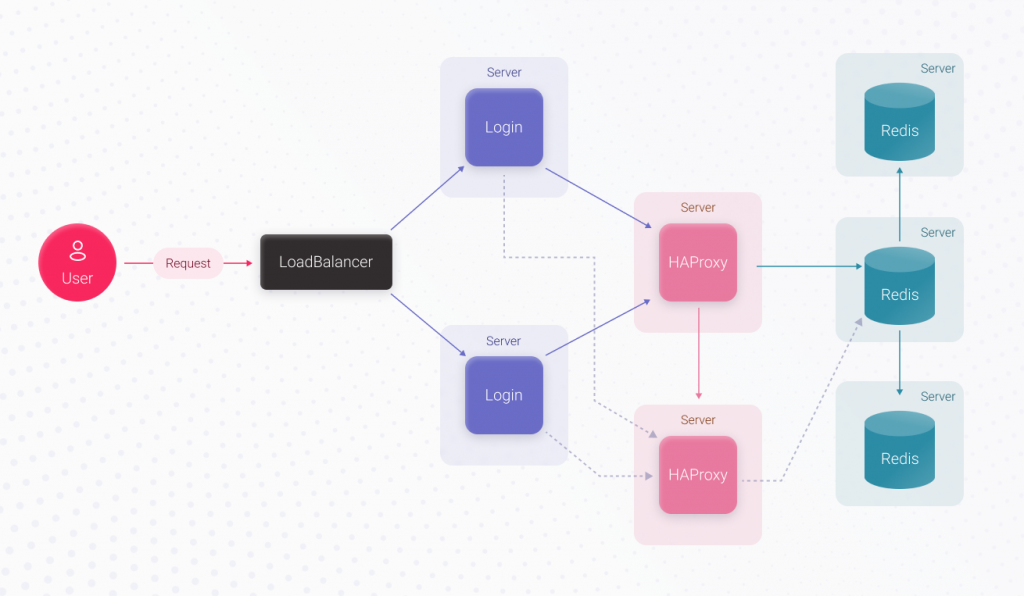
These losses can be avoided by putting in more effort. Adding an extra server for running the code and using a load balancer before it, plus moving Redis to a separate server, can do the trick. Here, UpTime will increase significantly because the login functionality is duplicated. If one login server becomes unavailable, the second can process user requests. Since Redis works separately, its stability doesn’t depend on the application servers. As a result, we made a massive leap towards increasing the login’s UpTime but spent more time. The login feature implementation takes X3 hours, which is more than X2.
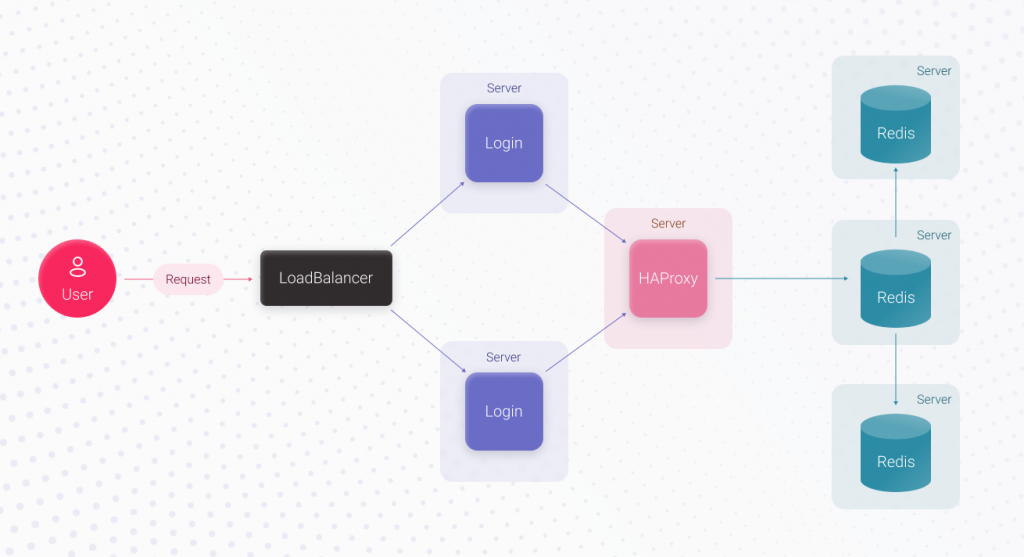
Now, simply speaking, the login’s UpTime depends on the UpTime of the server that runs Redis and the Redis itself. With AWS, there are guaranteed 4 hours of downtime per year since it’s the rented server’s downtime we can’t avoid, plus Redis’ downtime. To increase the login’s UpTime, we can replace the Redis server with a Redis cluster containing 3 servers. When the main Redis server crashes, the remaining ones will continue working, and the authorization process will work just fine.
For the application to know where the main server is and to which Redis server it must connect, before the cluster, we should use a proxy, for example, HAProxy. HAProxy can switch to a new main server in about 3 seconds if the main Redis server crashes. In this case, the Redis downtime will decrease to 3 seconds, but we’ll have to spend extra time implementing this functionality. Implementing the Login feature will take X4 hours, which is bigger than X3.
Now, the weakest link is HAProxy. If it crashes, the authorization process won’t recognize the main Redis server, and the developer’s or DevOps specialist’s involvement will be required. This issue can be solved by replicating HAProxy. Also, the application code should allow connecting to the replica HAProxy in case the primary HAProxy server is unavailable. Since connection timeout to the primary HAProxy server is less than3 seconds (this is a configurable parameter), our maximum downtime equals 3 seconds. Now, feature implementation will take X5 hours which is more than X4.
It’s rather unlikely, but the chances are never zero, that you’ll contact a more scrupulous vendor who will provide an estimation of a solution based on adopting JWT timeouts and Redis TTL to decrease the login downtime to one second. But it’s the line beyond which the territory of high-load systems begins, and your application is unlikely from this area. Although who are we to judge your application? You know it better.
Conclusions
By itself, each described option for implementing the Login feature is correct, and each estimate of labor costs for implementation is accurate. But the X5 option is many times more complex and labor-intensive than the X1. Vendors follow their experience and preferred way of making an estimation. Some choose the simple method described in the X1 approach, while others consider the possible risks and choose the X3 option. Finally, somebody always wants to foresee all potential issues and picks X5.
Which one should you choose? The answer is the one that meets your needs. To clarify them, you should communicate with a vendor and ask to explain how authorization and other features will work. There’s always the possibility that the simplest option will work for your specific app. In any case, there’s one thing you should remember. A vendor’s estimate is a document you can (and should) discuss to identify and refine requirements. This document can always be adjusted if the vendor underestimates or overestimates the project’s complexity. In order to start a rough estimate of your project, so that you have something to rely on, contact us and our specialists will be happy to discuss your idea.